Win The Clone Wars With Duplicate Filters

When you subscribe to multiple feeds covering the same topic, it’s often the case to see duplicates or near-duplicates in your feed. Usually, it becomes immediately obvious when you read your feeds within a folder. Consider the following case with two feeds from Ars Technica posting the same story:
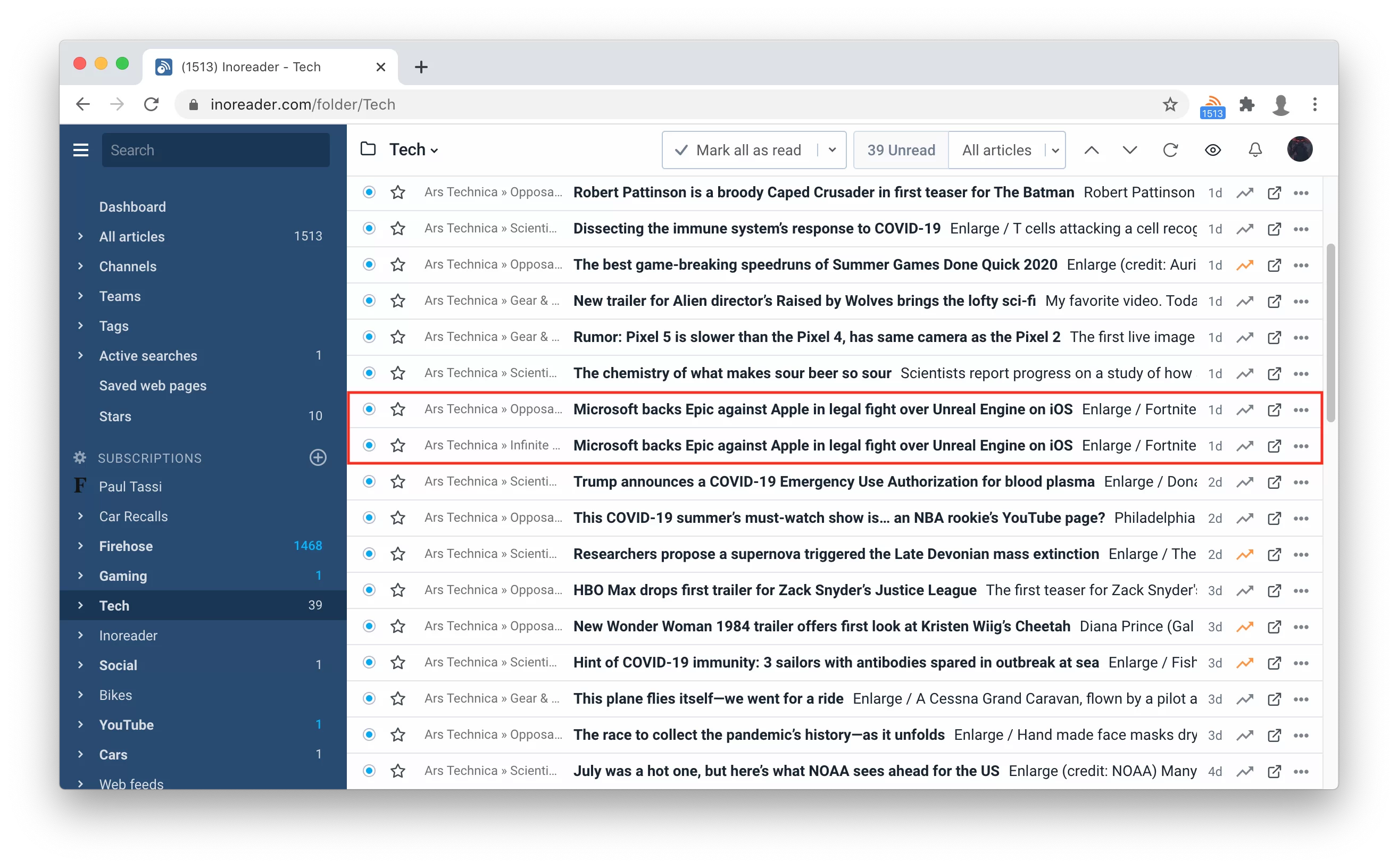
You can quickly spot those two articles and read just one of them. It’s a minor issue. However, it can be a bigger hassle when you read feed by feed because you cannot quickly identify them. Or sometimes they might not be adjacent to each other or simply reposts from different outlets. You just see the same story again, and after a while it becomes frustrating. Sometimes even a single feed can produce duplicates for various reasons. Inoreader does its best to prevent them from even entering the database, but feeds vary so much in their content and layout that it just happens sometimes.
The evolution of duplicate filtering
Inoreader has always had a very limited client-side global duplicate filter, available only for the web. It was operating only on articles received by your browser, so it wasn’t able to catch duplicates across different sections; worked only on inoreader.com and duplicate articles could still hit your rules and mobile apps. For some people, this was enough but to us, it always felt like a work-around for a very important feature.
Introducing backend-based duplicate filters
Today, after months of work and fine-tuning, we are launching our brand new, backend-based duplicate filters! Here are just some of the benefits:
- You now have the power to remove duplicates across feeds, folders, monitoring feeds, or even your whole account.
- You can choose to detect and remove “near duplicates”. We’ll explain that later, but it is BIG.
- Duplicate filters run continuously even when you are not using Inoreader, so your unread counters will be accurate and your rules won’t trigger on each duplicate.
- They work across the whole service, so once you set them up you won’t see duplicates on our web app, our mobile apps, or 3rd party apps (e.g. Reeder). Duplicates won’t even show up in your outgoing RSS feeds.
- You can manage all your filters in a single place from Preferences.
- You can view a log with all detected and removed duplicates for each filter.
Duplicate filters are available in our Pro plan.
Now for some real action
Just go to inoreader.com, or grab the latest version of our Android or iOS app.
To set up a new duplicate filter from the web interface, you just double click on a folder, feed, or “All articles” section. You can also right-click and choose “Feed properties”. You will get a popup similar to this:
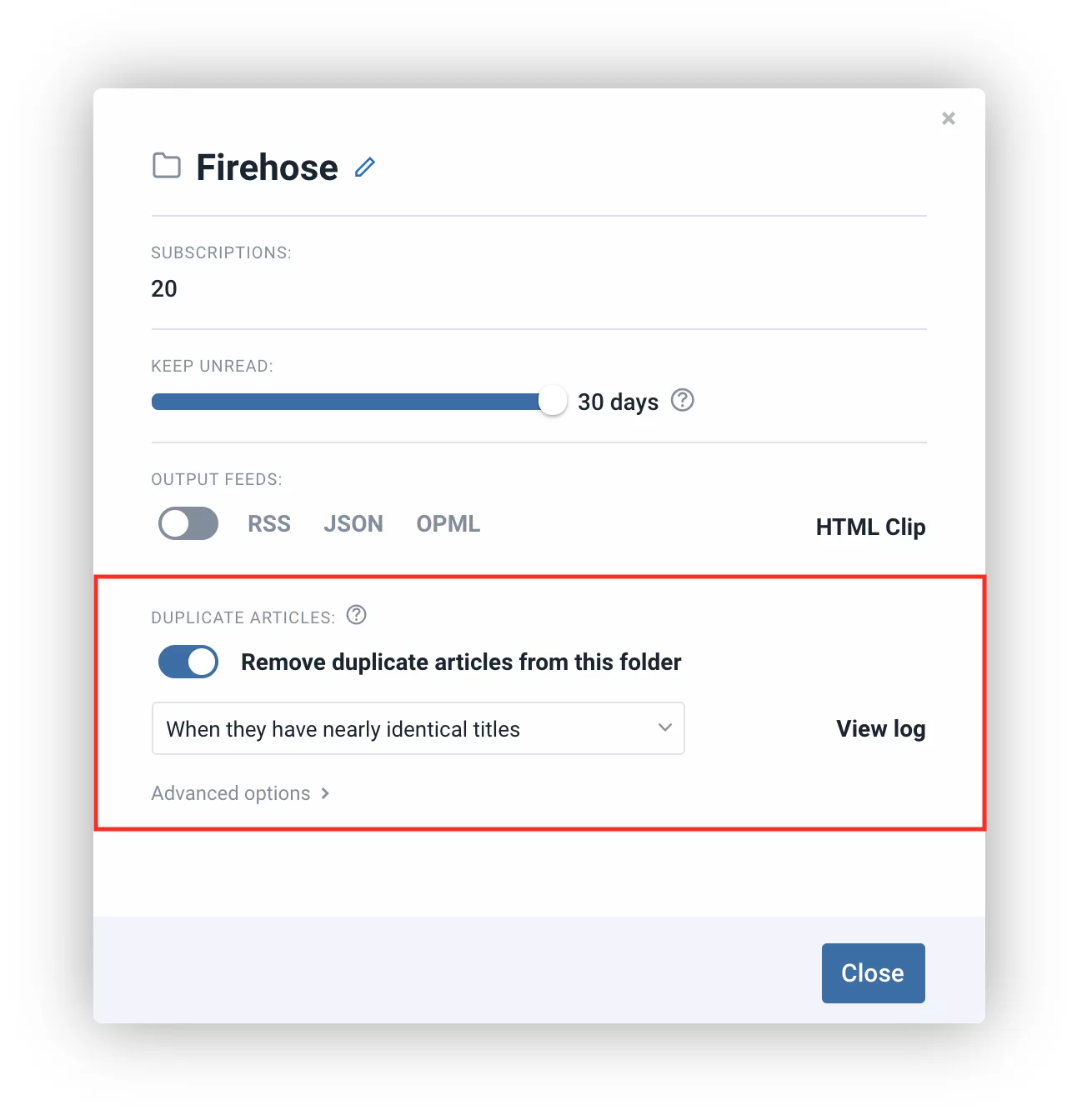
The same popup can be accessed in our mobile apps too, by swiping the feed or folder to the right and choosing “Feed properties”.
We are only interested in the highlighted section. You can quickly turn on/off your duplicate filter for this section from here. When turned on, you will need to choose the condition, which will be used to determine if an article is a duplicate. You can select between matching via URLs, exact titles, and nearly identical titles.
The filter is automatically saved when you make changes. The “Advanced options” menu (only available on inoreader.com) hides a few settings you can use to fine-tune your filter:
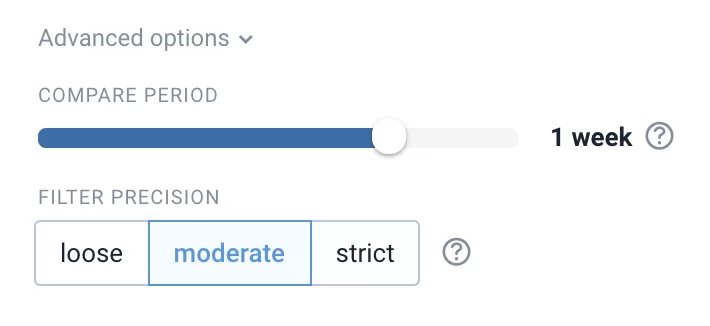
By default duplicate filters search for duplicates in the last week of the chosen section’s history. You can override this with the “Compare period” setting. For example, you might have a feed that posts something like “Daily digest” every day and you don’t want to catch that as duplicate. You will need to set a period shorter than one day in this case. Ideally, you will want this period to be as short as possible.
The second option – “Filter precision” tells the filter how aggressive it should be with identifying near-duplicates. If you choose “loose”, you will weed out а broader set of articles with similar titles, but it may also catch some articles that it shouldn’t.
Nearly identical articles
Few times in this post we have mentioned “near-duplicates” or nearly identical articles. Sometimes you have different feeds publishing the same story, but with a slightly modified headline. Machines are very quick (and accurate) in detecting true 1:1 matches, but “near-duplicates” are a completely different beast. Consider the following articles from the log:
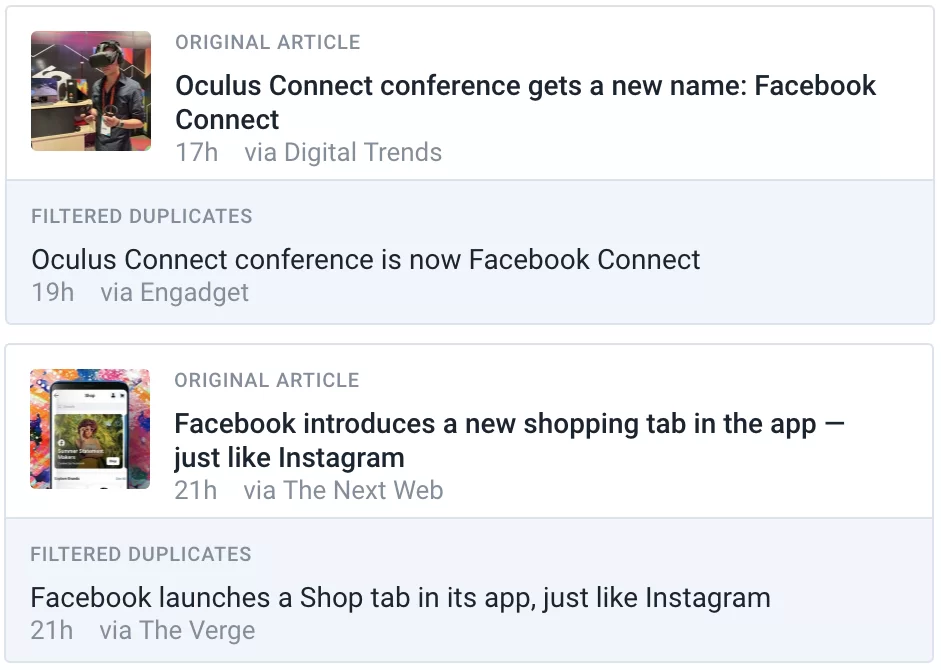
Both stories are covered by two different news outlets each, but with slightly different headlines. If you’ve already read the story from the first source (Original article), you will not see the second one (Filtered duplicates). Using this kind of filter is completely optional and if you prefer to read those stories from different perspectives, you can simply set your filter to match exactly and leave “near-duplicates” alone.
The nitty-gritty
Duplicate filters require an incredible amount of backend horse-power to run. Inoreader has to process between 150 and 200 new articles every second! But every single article can potentially match one of the hundreds of thousands of filters or rules. And while with rules we have a static set of conditions, with duplicate filters Inoreader needs to compare every new article with thousands of other articles from the history of the filter, just for a single filter. And this has to happen within а few milliseconds after the article has been fetched, so it doesn’t reach your account.
Over the years we have built a very scalable system to run computing tasks in parallel, so you shouldn’t worry about performance. All of this runs on our own infrastructure, which we frequently upgrade. For funding, we rely heavily on our Pro plan, so if you find Inoreader useful for your needs, consider upgrading.